I was just talking to Michael Weisberg, who is also visiting ANU currently, and he pointed me to this video showing a counterintuitive physics demonstration. I had seen the video before, so we started discussing how it might work. He pointed me to the explanation videos that the author of that video made, but they don’t really clarify things very much. When we tried to work it out ourselves, we came to the conclusion that it had to be impossible (unless there was slippage between the wheels or one of the surfaces) – until I realized one feature of the cart that I hadn’t noticed before.
Under the Ruler Faster than the Ruler
19 07 2009Comments : Leave a Comment »
Categories : Uncategorized
A Stronger Two-Envelope Paradox
24 05 2009Consider the standard two-envelope paradox – there are two envelopes in front of you, and all you know is that one of them has twice as much money as the other. It seems that you should be indifferent to which envelope you choose to take. However, once you’ve taken an envelope and opened it, you’ll see some amount 
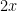

1.5x 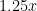
Of course, this reasoning doesn’t really work, because of course you always know more than just that one envelope has twice as much money as the other, especially if you know who’s giving you the money. (If the amount I see is large enough, I’ll be fairly certain that this one is the larger of the two envelopes, and therefore be happy that I chose it rather than the other.)
But it’s also well-known that the paradox can be fixed up and made more paradoxical again by imposing a probability distribution on the amounts of money in the two envelopes. Let’s say that one envelope has 
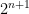

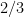
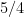
This is all fair enough – Dave Chalmers pointed out in his “The St. Petersburg Two-Envelope Problem” that there are other cases where A can be preferred to B conditional on the value of B, while B can be preferred to A conditional on the value of A, while unconditionally, one should be indifferent between A and B. This just means that we shouldn’t accept Savage’s “sure-thing principle”, which says that if there is a partition of possibilities, and you prefer A to B conditional on any element of the partition, then you should prefer A to B unconditionally. Of course, restricted versions of this principle hold, either when the partition is finite, or the payouts of the two actions are bounded, or one of the unconditional expected values is finite, or when the partition is fine enough that there is no uncertainty conditional on the partition (that is, when you’re talking about strict dominance rather than the sure-thing principle).
What I just noticed is that it’s trivial to come up with an example where we have the same pattern of conditional preferences, but there should be a strict unconditional preference for A over B. To see this, just consider this same example, where you know that the two envelopes are filled with the same pattern as above, but that 5% of the money has been taken out of envelope B. It seems clear that unconditionally one should prefer A to B, since it has the same probabilities of the same pre-tax amounts, and no tax. But once you know how much is in A, you should prefer B, because the 5% loss is smaller than the 25% difference in expected values. And of course, the previous reasoning shows why, once you know how much is in B, you should prefer A.
Violations of the sure-thing principle definitely feel weird, but I guess we just have to live with them if we’re going to allow decision theory to deal with infinitary cases.
Comments : 5 Comments »
Categories : Decision Theory, Probability
Probabilistic Proofs of Undecidable Sentences?
22 04 2009As I suggested (though perhaps not made as clear as I would have liked) in my forthcoming paper “Probabilistic Proofs and Transferability”, I think that probabilistic proofs can be used to provide knowledge of mathematical facts, even though there are reasons why we might think they should remain unacceptable as part of mathematical practice. (Basically, even though mathematicians gain knowledge through testimony all the time, there may be reasons for a methodological insistence that all mathematical arguments not rely essentially on testimony, the way probabilistic proofs (just like experiments in the natural sciences) do.) Given that this allows for a non-deductive means of acquiring mathematical knowledge, a natural question would be whether probabilistic proofs can be used to settle questions that are undecided by standard axiom sets. Unfortunately, I think the answer is probably “no”.
The sort of probabilistic proofs that I endorse aren’t just any old argument that isn’t deductively valid. In my paper, I contrast probabilistic proofs of the primality of a given number with certain arguments in favor of the Goldbach Conjecture and the Riemann Hypothesis, as well as lottery arguments. The primality arguments work by showing that if n is prime, then a certain result is guaranteed, while if n is composite, then the probability of the same sort of result is at most 1/4k, where k can be made as large as one wants by generating more random numbers. As a result the evidence “tracks” the truth of the claim involved (that is, the evidence is very likely if the claim is true and very unlikely if the claim is false).
In the case of the Goldbach Conjecture, one of the pieces of “probabilistic” evidence that we have is that none of the first several million even numbers is a counterexample to the claim. However, although this evidence is very likely if the claim is true, we have no good a priori bounds on how likely this evidence would be if the claim were false. Thus, the evidence may give us some reason to believe the Goldbach Conjecture, but it’s hard to see just how much more evidence we’d need in order for this to give us knowledge that the Goldbach Conjecture is in fact true.
In the case of the Riemann Hypothesis, I don’t have room (or the knowledge) to state all the relevant pieces of evidence, but in this case the evidence is more of the type of “inference to the best explanation”, but again lacks any sort of probabilistic bounds on the possibility of it arising in misleading cases. This is not to say that this type of evidence can’t provide knowledge – in fact, we may already have enough evidence to count as knowing that the Riemann Hypothesis is true, though I’m definitely not certain of this. At any rate, if this does provide knowledge, it’s of a different sort than probabilistic proof, and may well have its own problems for acceptability in the mathematical canon.
In “lottery cases”, we have strong probabilistic evidence for the claim that a particular ticket will not win (in particular, that this ticket is in a fair lottery, and that there are a billion separate tickets, exactly one of which is a winner). However, most people want to say that we don’t have knowledge of this claim. Again, at least part of the reason is that our evidence doesn’t track the truth of the claim – nothing about our evidence is sensitive to the ticket’s status, and the evidence is just as likely if the claim is false (that is, the ticket is a winner) as if it’s true (that the ticket isn’t a winner).
Therefore, it seems that for any sort of evidence that we’d count as a “probabilistic proof” that gives us knowledge of some mathematical claim, we’d want to have good bounds on the probability of getting such evidence if the claim were true, as well as good bounds on the probability of getting such evidence if the claim were false. At the moment, I can’t really conceive of ways of generating mathematical evidence where there would be clear bounds on these probabilities other than by randomly sampling numbers from a particular bounded set. (There may be possibilities of sampling from unbounded sets, provided that the sampling method doesn’t rely on a non-countably-additive probability, but it’s a bit harder to see how these sorts of things could be relevant.)
Now let’s consider some claim that is independent of Peano Arithmetic, and see if there might be any way to come up with a probabilistic technique that would give evidence for or against such a claim, that had the relevant probabilistic bounds.
Unfortunately, I don’t think there will be. Consider two models of PA – one in which the claim is true, and one in which it’s false. We can assume that one of these models is the standard model (that is, it just consists of the standard natural numbers) while the other is some end-extension of this model. If our probabilistic method involves generating natural numbers through some random process and then checking their properties, then this method will have the same probabilities of generating the same numbers if applied in either one of these models (since presumably, the method will only ever generate standard natural numbers, and not any of the extra things in the non-standard model). Thus, any result of such a test will have the same probability whether the statement is true or false, and thus can’t be sensitive in the sense demanded above.
Now, one might worry that this argument assumes that conditional probabilities will have to be probabilities given by considering a particular non-standard model. This clearly isn’t what we’re doing in the case of primality testing however – we don’t consider the probabilities of various outcomes in a model where n is prime and in a model where n is not prime, not least because we have no idea what a model of the false one would even look like.
However, I think this is what we’d have to do for statements that could conceivably be independent of PA. Consider any process that involves sampling uniformly among the integers up to k, and then performing some calculations on them. Knowing the truth of PA, we can calculate what all the possible results of such a process could be, and verify that these will be the same whether our independent statement is true or false. Since this calculation will tell us everything we could possibly gain from running the probabilistic process, and it hasn’t given us knowledge about the independent statement, the probabilistic process can’t either, since it adds no new information, and therefore no new knowledge.
If we allow for probabilistic processes that sample from all natural numbers (rather than just sampling uniformly from a bounded range of them) I think we still can’t get any relevant knowledge. Assuming that the sampling process must have some countably additive probability distribution, then for any ε there must be some sufficiently large N that the probability that the process never generates a number larger than N is at most ε. By the above argument, the process can’t tell us anything about the independent statement if it never generates a number larger than N. Therefore, the difference in probability of various outcomes given the statement and its negation can’t be any larger than ε. But since ε was arbitrary, this means that the difference in probabilities must be 0. Thus, the process still fails to meet the sensitivity requirement, and therefore can’t give knowledge about the independent statement.
Thus, we can’t get probabilistic information about independent claims. Of course, since many people will be willing to say that we have good reason to believe the Goldbach Conjecture, and the Riemann Hypothesis, on the evidence mentioned above, we may be able to get arguments of those sorts for independent claims. But such arguments aren’t really “probabilistic” in the sense standardly discussed.
Additionally, there are many claims independent of Peano Arithmetic that we can prove using standard mathematical means. Some examples include Goodstein’s Theorem, the Paris-Harrington Theorem, and Borel Determinacy. (The latter is in fact so strong that it can’t be proven in Zermelo set theory, which is ZF set theory without the Axiom of Replacement.) In fact, the arguments given above show that probabilistic methods not only fail to decide claims that are undecided in PA, but in fact fail to decide claims that are independent of substantially weaker systems, like Robinson arithmetic and probably even Primitive Recursive Arithmetic. Since basically everything that is of mathematical interest is independent of PRA (basically all it can prove is statements saying that a recursive function has a specific value on specified inputs, like “376+91=467”) this means that probabilistic proofs really can’t do much. All they can do is give feasible proofs of claims that would otherwise take a very long time to verify, as in the primality of a particular number.
Comments : 6 Comments »
Categories : Epistemology of Mathematics, Incompleteness Theorems, Probability
The Strong Free Will Theorem
6 02 2009Wow, it’s been about four months since I’ve posted here! Anyway, I’ll try not to continue that pattern in the future.
In the February issue of the Notices of the American Mathematical Society, John Conway and Simon Kochen have a paper explaining their “free will theorem”, which I believe strengthens it slightly from earlier versions. I had heard rumors of this theorem for a year or two, but had never seen more than an abstract, or a discussion in the popular media, so I couldn’t see the actual content of the theorem in order to see what it really says. So this paper was nice to see.
It’s important to see the actual statement, because the way it’s been summarized is basically as they put it, “It asserts, roughly, that if indeed we humans have free will, then elementary particles already have their own small share of this valuable commodity.” Which is a tendentious statement, to say the least, given that it uses a term like “free will”.
Here is the full statement of the theorem, from their paper:
SPIN Axiom: Measurements of the squared (components of) spin of a spin 1 particle in three orthogonal directions always give the answers 1, 0, 1 in some order.
The TWIN Axiom: For twinned spin 1 particles, suppose experimenter A performs a triple experiment of measuring the squared spin component of particle a in three orthogonal directions x, y, z, while experimenter B measures the twinned particle b in one direction, w . Then if w happens to be in the same direction as one of x, y, z, experimenter B’s measurement will necessarily yield the same answer as the corresponding measurement by A.
The MIN Axiom: Assume that the experiments performed by A and B are space-like separated. Then experimenter B can freely choose any one of the 33 particular directions w , and a’s response is independent of this choice. Similarly and independently, A can freely choose any one of the 40 triples x, y, z, and b’s response is independent of that choice.
The Free Will Theorem. The axioms SPIN, TWIN and MIN imply that the response of a spin 1 particle to a triple experiment is free—that is to say, is not a function of properties of that part of the universe that is earlier than this response with respect to any given inertial frame.
The definition of “free” used in the MIN axiom is the same as that used in the Free Will Theorem – some event is “free” in this sense just in case multiple versions of it are all compatible with everything before that event in any reference frame. Mathematicians express this notion in terms of functions, and philosophers would say that the event doesn’t supervene on anything outside the future light cone.
When we note this definition of “free”, it seems that the initial summary of the theorem is trivial – if some human action doesn’t supervene on the past in any way, then of course this is also true for some subatomic particle, namely, the first one whose movement would be different under the different choices of action by the human.
However, the theorem points out something stronger than this – nothing in the axioms involved assumes that the experimenter is a physical being made up of subatomic particles. Even if you think it’s a conceptual necessity that the experimenter (or at least, the experimenting apparatus) is made up of subatomic particles, nothing requires that there be a first such particle whose motion is different in the choices of how to set up the experiment. So without the theorem, it’s conceptually possible that human movements are free in the sense described, even though the motions of any specific particle are determined by the motions at earlier times, because human actions are at least in part composed of chains of motions of particles with no earliest member. So the theorem really does prove that indeterminacy at the human level requires indeterminacy at the particle level.
However, it seems to me that Conway and Kochen go on to make some bad interpretations of what this theorem says about freedom, determinism, and interpretations of quantum mechanics. They say, “our theorem asserts that if experimenters have a certain freedom, then particles have exactly the same kind of freedom.” This is true for a very specific type of freedom (namely, non-supervenience on the past) but their theorem says nothing else about any other kind of freedom, or whether their freedom has anything to do with the kind of freedom that matters. It may be that this kind of freedom is an important component of free will in the ordinary sense, but it may be that free will essentially requires not just non-supervenience, but also some sort of complex structure that just isn’t possible for the motions of individual particles.
They do make some good points about how the sort of freedom allowed for the particles is merely “semi-freedom” – that is, it is really spacelike separated pairs of particles whose motions are free, because the TWIN axiom says that the motions are in fact correlated in certain ways. They are right to point out that this means the freedom is different from “classically stochastic processes”, which clearly don’t provide any help in explaining free will. However, it really isn’t clear to me that this semi-freedom is any more help – correlations between twinned particles seem exceedingly unlikely to be relevant to the notion of free will.
“Granted our three axioms, the FWT shows that nature itself is non-deterministic. It follows that there can be no correct relativistic deterministic theory of nature. In particular, no relativistic version of a hidden variable theory such as Bohm’s well-known theory can exist.”
I agree that their axioms entail non-determinism. However, I don’t see why this should cause any trouble for the proponent of Bohm’s theory. It seems to me that a proponent of Bohm’s theory would just never grant the MIN axiom. Since the theory is deterministic, it entails that the choices of experimenters (assuming they are part of the physical world) aren’t free in the sense required by the axiom. Presumably, Bohmians are either compatibilists about free will (so that it doesn’t require freedom in the sense of the theorem) or insist that apparent free will is just an illusion. In either case, the seeming freedom of experimenters to set up their apparatus how they like gives us no evidence that this process is non-deterministic.
I suspect that a similar move can be made by the proponent of GRW theory, but I am unfamiliar with the details. They spend the last page or so of this paper engaged in a dialectic with a proponent of GRW theory who responded to some earlier papers of theirs, and give a modified version of the MIN axiom that they claim should be acceptable to the defender of GRW, but I suspect that a lot will depend on the interpretations of the words “independent”, “free”, and “choice” that they use.
In summary, I think the Free Will Theorem does a nice job of showing that a few facts about quantum mechanics (SPIN and TWIN) show that a certain type of macro-scale indeterminacy (MIN) entails a certain type of micro-scale indeterminacy. Additionally, the micro-scale indeterminacy is required not to be like most standard stochastic processes (because of the correlations over distances), so it may well be a place to look for interesting explanations of incompatibilist free will.
However, the theorem tells us nothing about compatibilism itself (which, contra Conway and Kochen, is not “a now unnecessary attempt to allow for human free will in a deterministic world”), because the theorem does nothing to prevent deterministic interpretations of quantum mechanics, whether Bohmian or otherwise. It may do something to constrain the shape that GRW-style theories can take, but this is less clear to me.
Comments : 10 Comments »
Categories : Uncategorized
Guessing the result of infinitely many coin tosses
26 09 2008I’ve stolen the title of a very interesting post by Andrew Bacon over at Possibly Philosophy. He considers a situation where there will be infinitely many coin flips occurring between noon and 1 pm, but instead of getting faster and faster, they’re getting slower and slower. In particular, one coin flip occurs at 1/n past noon for each integer n. He shows that there exists a strategy for guessing, where each guess may use information about how previous coin flips have come up (which sounds like it should be irrelevant, because they’re all independent 50/50 flips), such that one is guaranteed to get all but finitely many of the guesses correct. In particular, this means that although there is no first flip, there is a first flip on which one gets an incorrect guess, so up to that point one has successfully guessed the result of infinitely many independent fair coin tosses.
Check out his post to see the description of the strategy, or work it out yourself, before going on.
Anyway, I managed to figure this out, only because it’s formally identical to a game with colored hats that I had discussed earlier with math friends. But I think Andrew’s version with the coin flips is somehow even more surprising and shocking!
He begins his discussion with a discussion of a very nice paper by Tim Williamson showing that allowing infinitesimal probabilities doesn’t get us around the requirement that the probability of an infinite sequence of heads be 0. (Coincidentally, I’m currently working on a paper extending this to suggest that infinitesimal probabilities really can’t do much of anything useful for epistemological purposes.) Andrew concludes with a bit more discussion of these probabilistic issues:
Now this raises some further puzzles. For example, suppose that it’s half past twelve, and you know the representative sequence predicts that the next toss will be heads. What should your credence that it will land heads be? On the one hand it should be 1/2 since you know it’s a fair coin. But on the other hand, you know that the chance that this is one of the few times in the hour that you guess incorrectly is very small. In fact, in this scenario it is “infinitely” smaller in comparison, so that your credence in heads should be 1. So it seems this kind of reasoning violates the Principal Principle.
I was going to leave this following series of remarks as a comment, but it got bigger than I expected, and I liked this puzzle so much that I figured I should point other people to it in my own post anyway. So I don’t think that this puzzle leads to a violation of the Principal Principle. (For those who aren’t familiar, this principle comes from David Lewis’ paper “A Subjectivist’s Guide to Objective Chance” and states the seeming triviality that when one knows the objective chance of some outcome, and doesn’t know anything “inadmissible” specifically about the actual result of the process, then regardless of what other historical information one knows, one’s degree of belief in the outcome should be exactly equal to the chances. The only reason this principle is normally in dispute is in terms of figuring out what “inadmissible” means – if we can’t make sense of that concept then we can’t use the principle.)
The set of representatives involved in picking the strategy is a non-measurable set. To see this, we can see that the construction is basically a version of Vitali’s construction of a non-measurable set of reals. The only difference is that in the case of the reals we make use of the fact that Lebesgue measure is translation invariant – here we make use of the fact that measure is invariant under transformations that interchange heads and tails on any set of flips. Instead of the set of rational translations, we consider the set of finite interchanges of heads and tails. (This argument is basically outlined in the paper by Kadane, Schervish, and Seidenfeld, “Statistical Implications of Finitely Additive Probability”, which I’ve been working through more carefully recently for another paper I’m working on.)
This suggests to me that the set of situations in which you make the wrong guess on flip n may well be unmeasurable as well. (I haven’t worked out a proof of this claim though. [UPDATE: I have shown that it can sometimes be measurable depending on the strategy, and I conjecture that whenever it is measurable, it will have probability 1/2. See the comments for the argument.]) So from the outset (before the game starts) it looks like you can’t (or perhaps better, don’t) assign a credence to “I will make the wrong choice on flip n”. However, once it’s actually 1/n past twelve, you’ve got a lot more information – in particular, you know the outcomes of all the previous flips. I suspect that conditional on this information, the probability of making the wrong choice on flip n will just be 1/2, as we expect. (Of course, we have to make sense of what the right conditional probability to use here is, because we’re explicitly conditionalizing on a set of probability 0, as per Williamson.) Thus, there’s no violation of the Principal Principle when the time actually comes.
However, there does appear to be a violation of a principle called “conglomerability”, which is what my interest in the Kadane, Schervish, and Seidenfeld paper is about. One version of this principle states that if there is a partition of the probability space, and an event whose probability conditional on every event in this partition is in some interval, then the unconditional probability of that event must also be in this interval. In this case we’ve got a partition (into all the sequences of flips down to the nth) and the probability of guessing wrong conditional on each event in that partition is 1/2, and yet I’ve said that the unconditional probability is undefined, rather than 1/2.
I think I have a defense here though, which is part of my general defense of conglomerability against several other apparent counterexamples (including some in this paper and others by Seidenfeld, Schervish, and Kadane, as well as a paper by Arntzenius, Elga, and Hawthorne). The problem here is that the event whose unconditional probability we are interested in is unmeasurable, so it doesn’t even make sense to talk about the unconditional probability. In the case of the conditional probabilities, I’d say that strictly speaking it doesn’t make sense to talk about them either. However, conditional on the outcome of the flips down to the nth, this event is coextensive with something that is measurable, namely “the coin will come up heads” (or else perhaps, “the coin will come up tails”), because the sequence of flips down to that point determines which outcome I will guess for that flip. Thus these events have well-defined probabilities.
The only reason this situation of an apparent violation of conglomerability emerges is because we’re dealing explicitly with unmeasurable sets. However, I’m only interested in the application of probability theory to agents with a certain type of restriction on their potential mental contents. I don’t want to insist that they can only grasp finite amounts of information, because in some sense we actually do have access to infinitely many pieces of information at any time (at least, to the extent that general Chomskyan competence/performance distinctions suggest that we have the competence to deal with infinitely many propositions about things, even if in practice we never deal with extremely large sentences or numbers or whatever). However, I think it is reasonable to insist that any set that an agent can grasp not essentially depend on the Axiom of Choice for the proof that it exists. Although we can grasp infinitely much information, it’s only in cases where it’s nicely structured that we can grasp it. Thus, the strategy that gives rise to this problem is something that can’t be grasped by any agent, and therefore this problem isn’t really a problem.
Comments : 15 Comments »
Categories : Probability, Set Theory
The Role of Existence Proofs
13 09 2008When I was an undergraduate, I remember being very struck by some of the early results in the class I was taking on abstract algebra. Of course, I was eventually very struck by the results from Galois theory when we got there, but in the early parts of the class I was struck by the results proving the existence of the algebraic closure of a field, and proving the existence of a field of fractions for every integral domain. In particular, these seemed to me to validate the use of the complex numbers (once the reals were given) and the rational numbers (once the integers were given). I was still vaguely dissatisfied that we hadn’t yet had a proof of the existence of the integers, but I became happier when I saw the definition of the natural numbers as the smallest set containing 0 and closed under the successor operation, especially because this let proof by induction be a theorem rather than an axiom.
However, earlier this week (in conversation with Zach Weber, while visiting Sydney), I started realizing what I should have realized long ago, which is that these theorems really can’t be doing as much work in justifying our use of the various number concepts as I had thought when I was younger. Of course, these theorems are quite useful when talking about abstract fields or rings, but when we’re talking about the familiar complex, real, rational, and integer numbers, it’s no longer clear to me that these theorems add anything whatsoever. After all, what these theorems show is just that, by using some fancy set-theoretic machinery of ordered pairs and equivalence classes, we can create a structure that has all the properties of a structure that we already basically understood. Perhaps in the case of the complex numbers this mathematical assurance is useful (though even there we already had the simple assurance in the form of thinking of complex numbers as ordered pairs of reals, rather than as polynomials over R modulo the ideal [x2+1]), but for the rationals and negative numbers, our understanding of them as integers with fractional remainder, or as formal inverses of positive numbers, is already sophisticated enough to see that they’re perfectly well-defined structures, even before we get the construction as equivalence classes of ordered pairs of integers or naturals.
But this is all a sort of prelude to thinking about the two more famous set-theoretic reductions, that of the reals to Dedekind cuts (or Cauchy sequences) of rationals, and that of the naturals to the finite von Neumann ordinals. Unlike the others, I think the Cauchy and Dedekind constructions of the reals are quite useful – before their work, I think the notion of real number was quite vague. We knew that every continuous function that achieves positive and negative values should have a zero, but it wasn’t quite clear why this should be so. Also, I think intuitively there remained worries about whether there could be a distinct real number named by “.99999…” as opposed to the one named by “1”, not to mention the worries about whether certain non-convergent series could be summed, like 1-1+1-1+1….
But for the reduction of the naturals to the von Neumann ordinals, I think it’s clear that this should do no work in explicating the notion at hand. To prove that enough von Neumann ordinals exist to do this work, you already need a decent amount of set theory. (John Burgess’ excellent book Fixing Frege does a good job investigating just how much set theory is needed for this and various other reductions.) And while some of the notions involved are basic, like membership and union, I think the concept of sets of mixed rank (for instance, sets that have as members both sets, and sets of sets) already strains our concept of set much more than any of this can help clarify basic notions like successor, addition, and multiplication. One might even be able to make a case that to understand the relevant formal set theory one must already have the concept of an ordered string of symbols, which requires the concept of finite ordering, which is basically already the concept of natural numbers!
In some sense, this was one project that Frege was engaged in, and his greatest failure (the fact that his set theory was inconsistent) shows in a sense just how unnecessary this project was. At least to some extent, Frege’s set theory was motivated by an extent to show the consistency of Peano arithmetic, and clarify the concept of natural number. However, when his explanation failed, this didn’t undermine our confidence in the correctness of Peano arithmetic. The same thing would be the case if someone today were to discover that ZFC was inconsistent – most of the mathematics that we today justify by appeal to ZFC would still stand. We wouldn’t abandon Peano arithmetic, and I think we wouldn’t even abandon most abstract algebra, geometry, analysis, and the like, except perhaps in some cases where we make strong appeals to the Axiom of Choice and strange set-theoretic constructions.
Of course, Frege’s actual attempted reduction of the number concepts to set theory would have been a very nice one, and could help explain what we mean by number, because he reduced each number to the collection of all sets with that many elements. However, modern set theory suggests that no such collections exist (except in the case of the number 0), and the proposed reductions are much less illuminating.
So I wonder, what role do these proofs play, that demonstrate the existence of structures that behave like the familiar natural numbers, integers, rationals, reals and complex numbers? I’ve suggested that in the case of the reals it may actually do important work, but I’m starting to be skeptical of most of the other cases.
Comments : 7 Comments »
Categories : Uncategorized
Theorems from Biology
16 07 2008Thanks to Ars Mathematica, I found an interesting article (.pdf) demonstrating some recent theorems in pure mathematics that emerged primarily from doing research arising from biology (construction and inference of phylogenetic trees in particular). Unfortunately, I couldn’t really work through the math enough to really understand any of the theorems.
But really, it doesn’t seem terribly surprising that interesting theorems arise when one considers sufficiently interesting applications of mathematics. These theorems don’t appear to be like the one I mentioned earlier, where the result could be very strongly supported by scientific argument – they’re the more standard results of applied mathematics that mathematicians came up with and turned out to be applicable. But the work was still motivated by the science.
I don’t see any particularly strong argument here that biology will be more productive in this way than physics has been, but it seems to me that any field that applies sufficiently interesting mathematics will lead to the development of new mathematics that eventually turns out to be interesting for purely mathematical reasons as well. Philosophy led to mathematical logic, and the Gödel results in particular, not to mention the results of social choice theory (which I suppose could equally be attributed to economics or political science or a variety of other social scientific enterprises). I don’t know about much mathematics that can be attributed to chemistry, but I did see a very interesting lecture at last year’s Canada/USA Mathcamp about levels of topological classification relevant for describing chirality of molecules (I don’t know whether this has spurred interesting new areas of topology).
I suppose the main problem is just that the paradigm of applied mathematics that many people have (or at least I do) is differential equations. Once we see that so much of mathematics is applied, or can be applied, and that the applications very often lead to interesting new methods of development that occasionally lead to substantial insights within mathematics itself, it should be clear that whatever the status of Hardy’s claims that the best mathematics is essentially pure, there’s no reason for mathematics to cut itself off from the other sciences, or even to seek to remain pure at all times.
Comments : 1 Comment »
Categories : Indispensability
Computer Proofs Give A Priori Knowledge
30 06 2008I just read a very interesting paper by Tyler Burge on computer proofs. (“Computer Proofs, Apriori Knowledge, and Other Minds”, Phil. Perspectives 12, 1998 ) I suspect that many mathematicians will find the paper quite interesting, as well as philosophers. His major claim is that, contrary to most assumptions, computer proofs can in fact give mathematicians a priori knowledge of their theorems.
An important question here is just what it means for knowledge to be a priori. Burge defines the notion as just stating that the knowledge doesn’t depend for its justification on any sensory experience – however, he allows that a priori knowledge may depend for its possibility on sensory experience. This account allows for the knowledge that red is a color to be a priori, even though having this knowledge requires having sensory experience of red in order to have the concepts required to even formulate the idea. Burge’s main goal here is to defend a sort of rationalism, which is the claim that a lot of a priori knowledge is possible, so it’s somewhat important that his account of the a priori is broader than one might initially think. One might worry that this waters down the notion of the a priori so much as to make this form of rationalism uninteresting, but I think it still gets at some interesting distinctions. For instance, his account will end up saying that almost all mathematical knowledge is a priori (or at least, can be) while very little knowledge in the other sciences can be. This may be very interesting for those wanting to claim a principled difference between mathematics and the other sciences. (For those of you familiar with the talk I’ve been giving recently about probabilistic proofs, I suspect that in addition to a priority, the notion I call “transferability” gives mathematics a lot of its specific character, but that’s a different issue.)
The biggest premise that Burge asks us to grant is that most ordinary mathematical knowledge that doesn’t rely on computer proofs is itself a priori. In order to grant this, we have to grant that testimony can preserve a priority, since very many mathematical proofs depend on theorems or lemmas that the author has never worked through, but believes just on the basis of testimony (having skimmed a proof, or even just read a result published in another paper). For an extreme instance, consider the classification of finite simple groups – no one has worked through all the steps in the proof, yet it seems at least plausible that our knowledge of the result is a priori in some interesting sense. The sense that Burge suggests this is is that although a mathematician may depend on testimony for her knowledge of the theorem, the actual steps in the justification of the result were a priori for whoever carried them out.
Burge needs to do a lot of work to suggest that this transfer of knowledge through testimony can preserve a priority – he ends up showing that we can often get a priori justification for the claim that there are other minds by the same means. He suggests that the very fact that some part of the world appears to express a propositional content gives us some defeasible a priori reason to believe the content of that claim, and also to believe that some mind somewhere is responsible for that content, even if at some remove. (That is, although books and computers can display things expressing propositional contents despite lacking minds themselves, the only reason they normally succeed in doing this is because some mind somewhere gave them this capacity, either by directly putting the symbols on them, or causing them to shuffle symbols in intelligible ways. Although you often get significant and meaningful patterns in nature, it’s exceedingly rare that something natural appears to express a specific proposition. See Grice for more on this.)
Once we’ve got this idea that testimony can preserve a priority, it becomes more plausible to think that computer proofs can generate a priori knowledge. However, he still has to go through a lot of work to argue that we have an undefeated warrant for believing the claims of the computer. Clearly, in many cases where someone utters a sentence, we have strong reason to doubt the truth of that sentence, unless we have positive reason to believe that the person is a very skilled mathematician. In the case of something like Fermat’s Last Theorem, it seems that even that is insufficient (after all, even Fermat’s word on the theorem really doesn’t seem like sufficient grounds for knowledge). Burge needs to do some fancy footwork to argue that the means by which we build up our trust in a source of utterances can itself be a priori, since it only depends on success of apparent utterances, and not on the fact that the source of the utterances really is as it appears to be. (It doesn’t matter to me whether Andrew Wiles (whom Burge embarrassingly refers to as Michael Wiles!) is a real person, a computer, or a simulation in the Matrix – he’s done enough to prove that he’s a reliable source of knowledge of complicated mathematical statements of certain forms.)
I think in the end, Burge spends a lot of time focusing on the wrong sorts of support for the reliability of a person or computer who claims to have proved something difficult. He mostly focuses on the fact that this source has gotten many other difficult statements correct before. I think in actual mathematical practice the more important criterion is that the outline of the strategy used looks much more promising than previous attempts at the problem, and the source has given good indication of being able to carry out particular sub-parts of the proof. Burge does deal with this justification, but in not as central a way as might be desired.
So I think Burge has come up with some interesting arguments that computer proof still preserves the fact that most mathematical knowledge is a priori, even though I think he makes some mathematical errors in focus and about particular claims of mathematical history. I think his defense of computer proof also still allows for the fact that other mathematical arguments (like DNA computing, for instance) really don’t preserve a priority. After all, in these cases, the computer isn’t going through something like a reasoning process, but rather is doing something more like an observation of an experiment. The way that most ordinary computers process data still shares abstract features of reasoning that are important for a notion of the a priori, in ways that DNA computing don’t. (If we didn’t grant this, then it might seem that there’s no such thing as any a priori knowledge, since we always in some sense rely on the physical reliability of our own brains – he gives some good arguments for why we should dismiss this worry.)
I think this sort of epistemology of mathematics is probably of much more practical interest for mathematicians than the standard questions of ontology and logic that more traditional philosophy of mathematics deals with.
Comments : 7 Comments »
Categories : Epistemology of Mathematics
An Economic Argument for a Mathematical Conclusion
27 04 2008How valuable is an income stream that pays $1000 a year in perpetuity? Naively, one might suspect that since this stream will eventually pay out arbitrarily large amounts of money, it should be worth infinitely much. But of course, this is clearly not true – for a variety of reasons, future money is not as valuable as present money. (One reason economists focus on is the fact that present money can be invested and thus become a larger amount of future money. Another reason is that one may die at any point, and thus one may not live to be able to use the future money. Yet another reason is that one’s interests and desires gradually change, so one naturally cares less about one’s future self’s purchasing power as one’s current purchasing power.) Thus, there must be some sort of discount rate. For now, let’s make the simplifying assumption that the discount rate is constant over future years, so that money in any year from now into the future is worth 1.01 times the same amount of money a year later.
Then we can calculate mathematically that the present value of an income stream of $1000 a year in perpetuity is given by the sum 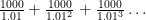
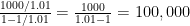
The economic argument goes as follows. If money in any year is worth 1.01 times money in the next year, then in an efficient market, there would be investments one could make that pay an interest of 1% in each year. Investing $100,000 permanently in this and taking out the interest each year gives rise to this income stream, and thus one can fairly trade $100,000 to receive this perpetual income stream, so they must be equal in value. We don’t need to sum the series at all.
Now perhaps there is a sense in which the mathematical argument given above and the economic argument given below can be translated into one another, but it’s far from clear to me. Thus, it looks like at least sometimes, economic intuition can solve mathematical problems. People often talk about the “unreasonable effectiveness of mathematics in the sciences”, but here I think I have another example of the unreasonable effectiveness of the sciences in mathematics.
Comments : 3 Comments »
Categories : Epistemology of Mathematics, Probability
Updates
24 04 2008I suppose it’s been about four months since I last updated here – partly that’s been because I was busy with the job search, and partly it’s because I’m still finishing up my dissertation. Anyway, I’m glad to announce that I’ll be taking a tenure-track position at USC starting next year. Additionally, I’ll be spending two semesters as a post-doc in the RSSS department of philosophy at ANU, most likely from June to December of 2008 and of 2009. Part of the reason why it took so long to sort out my job situation is that I’ve been trying to make sure these two positions will be compatible. (Part of the reason was also that the tenure-track offers I did receive were all offered to other people first, who turned them down.) At any rate I’m very excited to be affiliated with both of these institutions. The other job offers I had were also quite attractive, and it was very hard to turn them down.
I’ve missed a few things in the past few months that I should mention. My second book review was published, as was my first actual paper:
Review of Jody Azzouni’s Tracking Reason
“The Role of Axioms in Mathematics”
Plus, I also got a paper accepted to Mind, and a paper (with Mark Colyvan) accepted to The Australasian Journal of Logic!
Also, since I was tagged by Shawn, here’s the 5th, 6th, and 7th sentences of p. 123 of the book that happened to be closest to me when I read his post (which is Roger Penrose’s, The Road to Reality, which I’ve been using so far to refresh my multivariable and complex analysis, and hope to eventually learn a bit of physics from).
From the complex perspective, we see that
is indeed a single function. The one place where the function ‘goes wrong’ in the complex plane is the origin
. If we remove this one point from the complex plane, we still get a connected region.
From now on I hope I’ll be back to more regular posting.
Comments : 4 Comments »
Categories : Announcement

Recent Comments